
Initial design
This document covers some of the initial design for
kind.NOTE: Some of this is out of date relative to what is currently implemented. This mostly exists for historical purposes, the the original proposal covers some more details.
Going forward the design principles may be more relevant.
Overview 🔗︎
kind or kubernetes in docker is a suite of tooling for local
Kubernetes “clusters” where each “node” is a Docker container.
kind is targeted at testing Kubernetes.
kind is divided into go packages implementing most of the functionality, a
command line for users, and a “node” base image. The intent is that the kind
suite of packages should eventually be importable and reusable by other
tools (e.g. kubetest)
while the CLI provides a quick way to use and debug these packages.
For the original proposal by Q-Lee see the kubernetes-sig-testing post (NOTE: this document is shared with kubernetes-sig-testing).
In short kind targets local clusters for testing purposes. While not all
testing can be performed without “real” clusters in “the cloud” with provider
enabled CCMs, enough can that we want something that:
- runs very cheap clusters that any developer can locally replicate
- integrates with our tooling
- is thoroughly documented and maintainable
- is very stable, and has extensive error handling and sanity checking
- passes all conformance tests
In practice kind looks something like this:
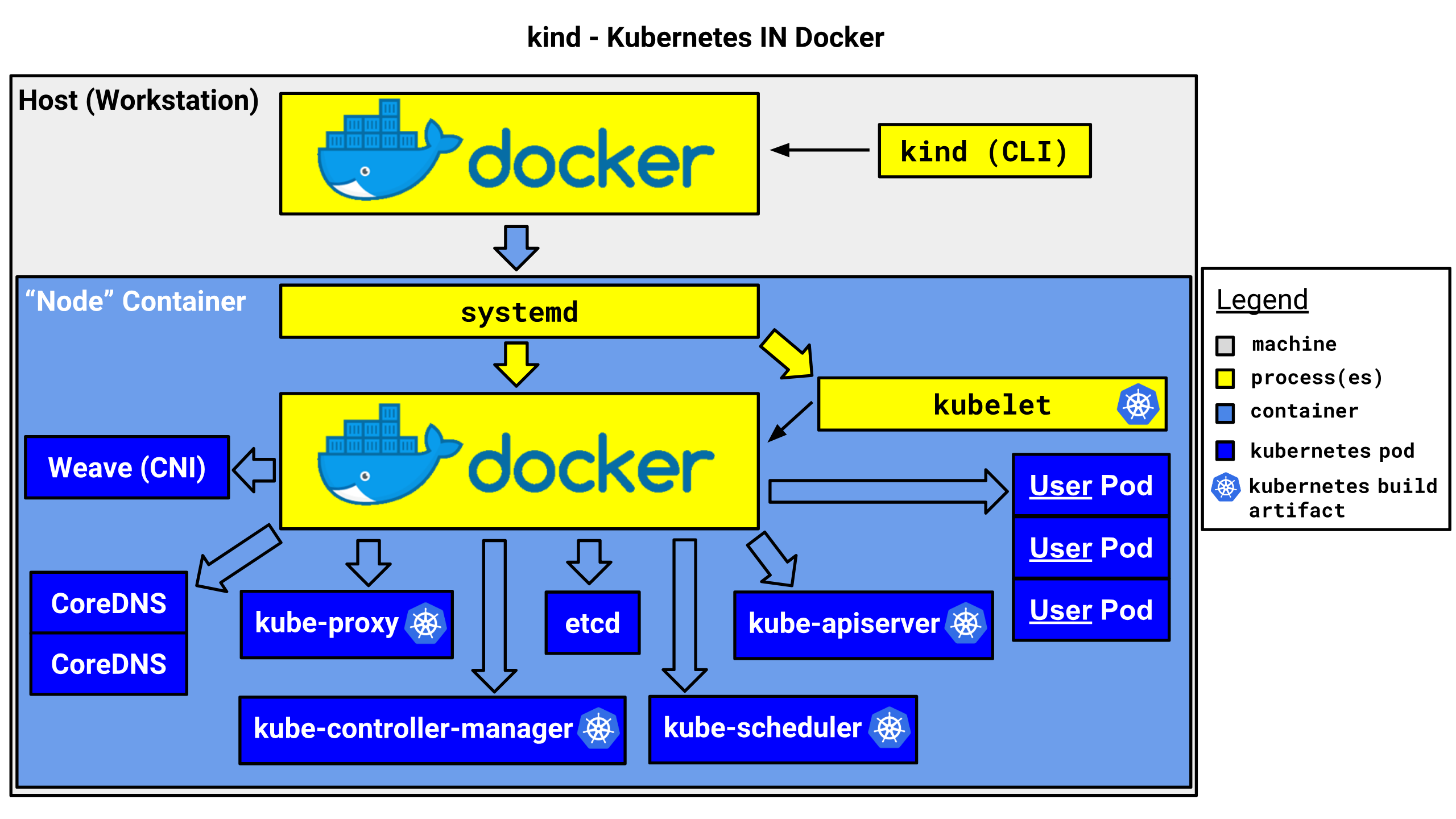
Clusters 🔗︎
Clusters are managed by logic in pkg/cluster, which the
kind cli wraps.
Each “cluster” is identified by an internal but well-known docker object label key, with the cluster name / ID as the value on each “node” container.
We initially offload this type of state into the containers and Docker.
Similarly the container names are automatically managed by kind, though
we will select over labels instead of names because these are less brittle and
are properly namespaced. Doing this also avoids us needing to manage anything
on the host filesystem, but should not degrade usage.
The KUBECONFIG will be bind-mounted to a temp directory, with the tooling
capable of detecting this from the containers and providing helpers to use it.
Images 🔗︎
To run Kubernetes in a container, we first need suitable container image(s). A single standard base layer is used, containing basic utilities like systemd, certificates, mount, etc.
Installing Kubernetes etc. is performed on top of this image, and may be cached in pre-built images. We expect to provide images with releases already installed for use in integrating against Kubernetes.
For more see node-image.md.
Cluster Lifecycle 🔗︎
Cluster Creation 🔗︎
Each “node” runs as a docker container. Each container initially boots to a
pseudo “paused” state, with the entrypoint waiting for SIGUSR1.
This allows us to manipulate and inspect the container with docker exec ...
and other tools prior to starting systemd and all of the components.
This setup includes fixing mounts and pre-loading saved docker images.
Once the nodes are sufficiently prepared, we signal the entrypoint to actually “boot” the node.
We then wait for the Docker service to be ready on the node before running
kubeadm to initialize the node.
Once kubeadm has booted, we export the KUBECONFIG, then apply an overlay network.
At this point users can test Kubernetes by using the exported kubeconfig.
Cluster Deletion 🔗︎
All “node” containers in the cluster are tagged with docker labels identifying the cluster by the chosen cluster name (default is “kind”), to delete a cluster we can simply list and delete containers with this label.